UnityShader-渲染流水线
UnityShader-渲染流水线
渲染流程
计算机从一系列顶点数据(POSITION)、纹理(TEXCOORD)等信息出发,把这些信息最终转换成一张二维图像显示在屏幕上。
渲染流程可分为3个阶段:应用阶段(Application Stage)、几何阶段(Geometry Stage)、光栅化阶段(Rasterizer Stage)
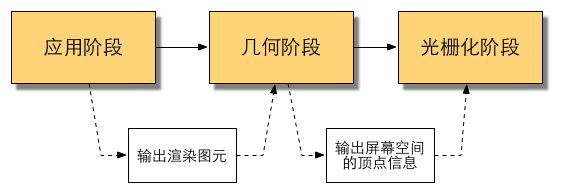
应用阶段
通常由CPU负责实现,这一阶段的主要任务:
- 准备好场景数据。如摄像机位置、视锥体、场景模型、使用光源等
- 粗粒度剔除工作。把不可见的物体剔除
- 设置每个模型的渲染状态。包括材质、纹理、Shader等
这一阶段输出渲染所需的几何信息,即渲染图元(rendering primitives)。渲染图元一般是点、线、三角面等
几何阶段
这一阶段处理和绘制相关的操作。决定需要绘制的图元是什么,怎样绘制和在哪里绘制(what, how, where)。该阶段在GPU上进行。
主要任务:把顶点坐标变换到屏幕空间中,即输出屏幕空间的顶点信息,再交给光栅器进行处理。这一阶段将会输出屏幕空间的二维顶点坐标、每个顶点对应的深度值、着色等相关信息,并传递给下一个阶段
光栅化阶段
这一阶段利用上个阶段传递的数据来产生屏幕像素,渲染出最终图像。
该阶段输入的信息为屏幕坐标系下的顶点位置以及它们相关的额外信息,如深度值(z坐标)、法线方向、视角方向等
主要任务:决定每个渲染图元中哪些像素应该被绘制在屏幕上。它需要对逐顶点数据(包括纹理坐标、顶点颜色等)进行插值,再进行逐像素处理。也就是说,计算每个图元覆盖了哪些像素,以及为这些像素计算它们的颜色
软件/硬件之间的联系
CPU和GPU之间的通信
该过程对应渲染流水线中的应用阶段。对于CPU而言,应用阶段可以分为一下阶段:
- 把数据加载到显存(Video Random Access Memory, VRAM)中。这一阶段加载的数据包括但不限于顶点的位置信息、法线方向、顶点颜色、纹理坐标等
- 设置渲染状态。即定义场景中的网格如何被渲染,例如顶点\片元着色器的选择、光源属性、材质等
- 调用Draw Call。CPU发送一个命令给GPU。让GPU开始进行渲染,该命令会指向需要被渲染图元的列表
CPU、OpenGL/DirectX、显卡驱动和GPU之间的联系
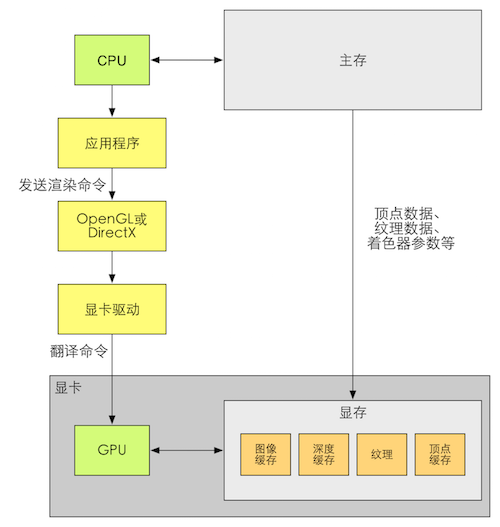
GPU流水线
GPU流水线即GPU的渲染过程。对应于渲染流水线中的几何阶段和光栅化阶段
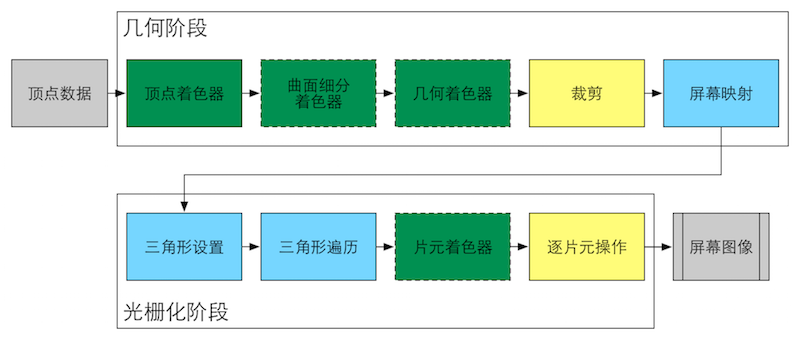
绿色:该流水线阶段是完全可编程控制的,实线表示必须实现,虚线表示该阶段可选
黄色:该流水线阶段可配置但不可编程
蓝色:该流水线阶段由GPU固定实现,开发者没有任何控制权
顶点着色器(Vertex Shader)
- 完全可编程
- 通常用于实现顶点的空间变换、顶点着色
- 处理单位:顶点,即每个输入顶点都会调用一次顶点着色器,顶点着色器不能创建和销毁顶点,且每个顶点相对独立(方便GPU并行计算)
- 主要工作:
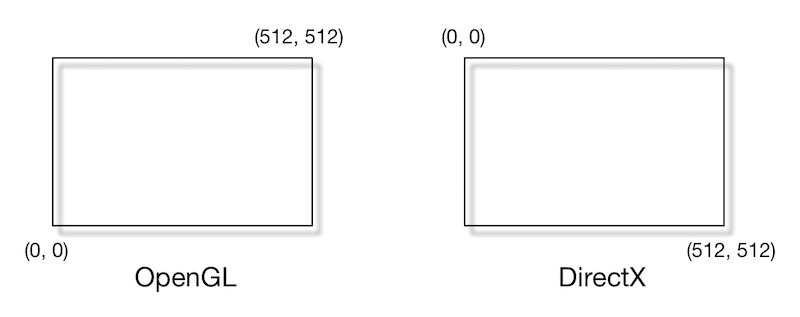
- 坐标变换。将顶点坐标从模型空间转换到齐次裁剪坐标空间(什么是齐次坐标? - 知乎 (zhihu.com)),再由硬件做透视除法转换到**归一化的设备坐标(Normalized Device Coordinates, NDC)**。在OpenGL中,NDC的z分量在[-1, 1]之间,而DirectX中,z分量在[0, 1]之间
- 逐顶点光照
- 输出后续阶段所需数据

注:根据原书的说法,右图应该是处于NDC下的坐标
曲面细分着色器(Tessellation Shader)
- 可选着色器
- 用于细分图元
几何着色器(Geometry Shader)
- 可选着色器
- 用于执行逐图元(Pre-Primitive)的着色操作,或者被用于产生更多的图元
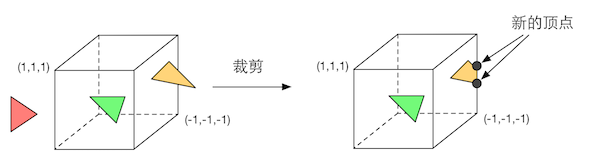
裁剪(Clipping)
- 将不在摄像机视野内的顶点裁剪掉,并剔除某些三角图元的图片(区别于应用阶段的粗粒度剔除工作,它只是将不可见物体剔除,不会涉及图元和片元),可以使用自定义的裁剪平面来配置裁剪区域。也可以通过指令控制裁剪三角图元的正面还是背面。
屏幕映射(Screen Mapping)
- 不可配置和编程
- 负责把每个图元的坐标(输入坐标仍然是三维坐标,范围在单位立方体内)转换到屏幕坐标系中,会经历一个缩放的过程,输入的z坐标不会做任何处理
- 屏幕坐标系和z坐标一起构成窗口坐标系(Window Coordinates)
- 屏幕映射得到的屏幕坐标决定了这个顶点对应屏幕上哪个像素以及距离这个像素有多远
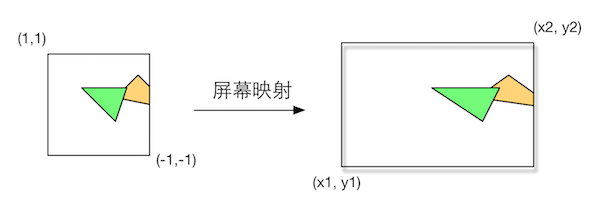
- 屏幕坐标系在OpenGL和DirectX之间存在差异,这可能导致图像倒转
三角形设置(Triangle Setup)
- 开发者没有任何控制权
- 该阶段会计算光栅化一个三角网格所需的信息,根据三角网格的顶点数据(输入数据)得到整个三角网格对像素的覆盖情况
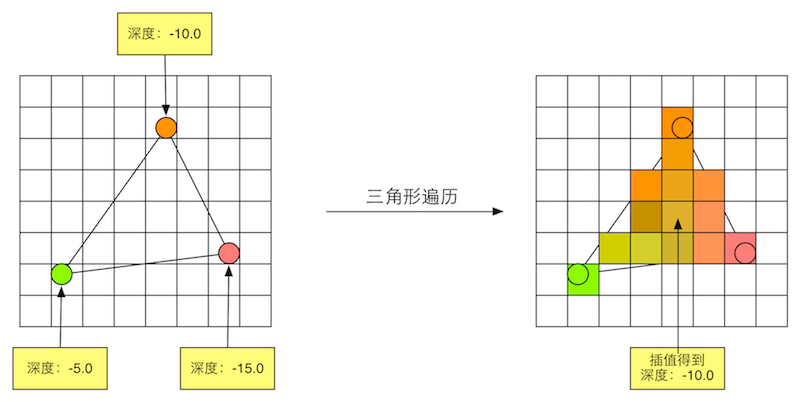
三角形遍历(Triangle Traversal)
开发者没有任何控制权
检查每个像素是否被一个三角网格所覆盖,如果被覆盖,则生成一个片元(fragment)
该阶段也被称为扫描变换(Scan Conversion)
三角形遍历阶段会根据上一个阶段的计算结果来判断一个三角网格覆盖了哪些像素,并使用三角网格的3个顶点信息对整个覆盖区域的像素进行插值
关于该阶段对哪些信息进行了怎样的插值(如法线插值、纹理插值等),可以参考OpenGL的官方教程OpenGL tutorial09
简单来说,每个顶点的法向量由构成它的三角形的法向量的平均值构成,而三角形内部的法向量由三角形的顶点插值构成,这样,如果物体不是平坦的(即三角形图元不在一个平面上),那么图元内的法向量方向也会不同,这样能够使得计算得到的光照更加真实
插值对于纹理坐标的应用也类似,这些坐标作为模型的一部分定义在每个顶点上。为了用贴图覆盖三角形你必须对每个像素进行一样的插值操作并给每个像素定义正确的纹理坐标,这些坐标都是插值的结果
片元:包含很多状态的集合,这些状态用于计算每个像素的最终颜色。这些状态包括了屏幕坐标、深度信息,以及其他从几何阶段输出的顶点信息,例如法线、纹理坐标等
片元着色器(Fragment Shader)
- 完全可编程
- 用于实现逐片元(Pre-Fragment)的着色操作,输出一个或者多个颜色值
- 该阶段完成纹理采样操作( Tex2D(texture, uv) )
逐片元操作(Pre-Fragment Operations)
- 负责执行很多重要工作,如修改颜色、深度缓冲、进行混合等,在DirectX中被称为输出合并阶段(Output-Merger)
- 决定每个片元的可见性,如深度测试、模板测试等
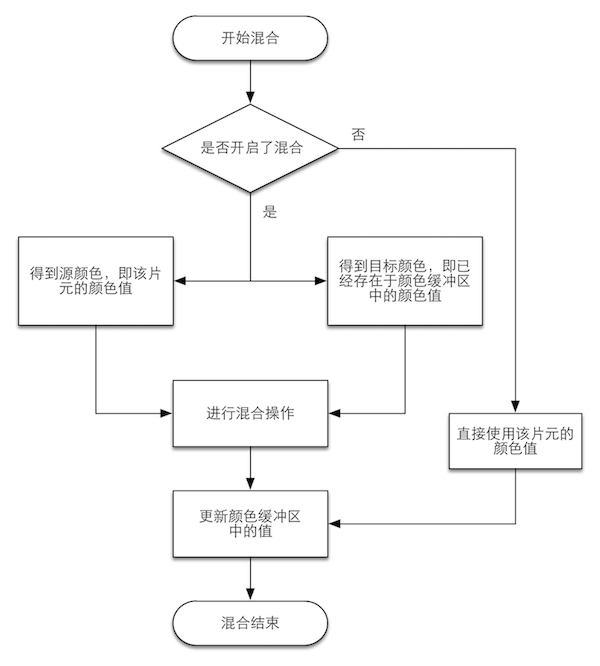
- 如果一个片元通过了所有测试,就需要把这个片元的颜色值和已经存储在颜色缓冲区中的颜色进行合并,或者说混合
- 该阶段高度可配置,如关闭深度写入(ZWrite Off),定义混合方法(Blend SrcAlpha OneMinusSrcAlpha)
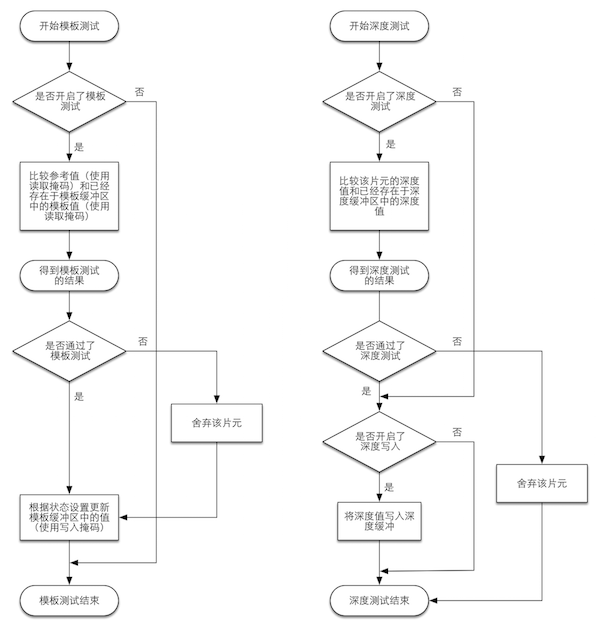
模板测试(Stencil Test)
TODO
深度测试(Depth Test)
根据片元的深度进行比较,将没有通过测试的片元舍弃
和模板测试不同的是,如果一个片元没有通过深度测试,则没有权利更改深度缓冲区的值;如果通过测试,可以指定是否覆盖掉原有深度值,即开启/关闭深度写入
模板测试和深度测试的简要过程如下:
混合(Blend)
- 对于半透明物体,需要使用混合操作来让物体看起来透明
- 混合操作高度可配置,通过设置混合函数能够实现不同的混合效果
Early-Z技术
对于大部分GPU来说,为了避免 计算被舍弃片元的颜色 造成造成的性能浪费,它们会尽可能在执行片元着色器之前就进行这些测试
但是,提前测试的结果可能与片元着色器的一些操作冲突,例如,在透明度测试中,需要在片元着色器中手动进行测试(调用clip函数),这将导致GPU禁用提前测试,降低性能
GPU采用双重缓冲(Double Buffering)策略避免看到正在进行光栅化的图元
关于Draw Call
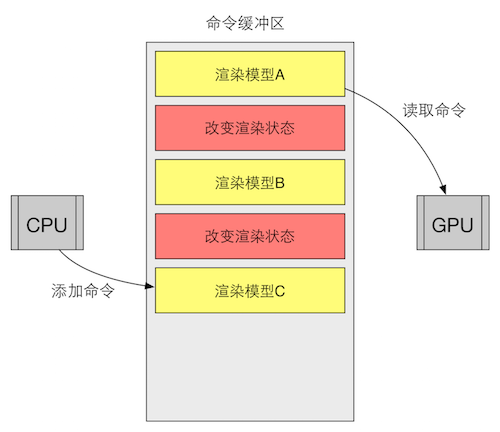
命令缓冲区(Command Buffer)
让CPU和GPU能够并行工作。CPU向其中添加命令,GPU从中取出命令,添加和读取过程相互独立(生产者和消费者问题)
批处理方法(Batching)
由于每次调用Draw Call,CPU需要向GPU发送很多内容,该提交过程非常影响性能,因此对于静态物体,可以将网格合并后批量发送,但是对于动态物体,由于每一帧都要合并后发送,可能会在性能上造成影响
固定管线渲染
在较旧的GPU上实现的渲染流水线,除非考虑兼容,不然不要使用
其他:
关于批处理:Wloka M. Batch, Batch, Batch: What does it mean?[C]//Presentation at game developers conference. 2003.
关于实时渲染:Alkenine-Moller T, Haines E, Hoffman N. Real-time rendering[M]. CRC Press, 2008.