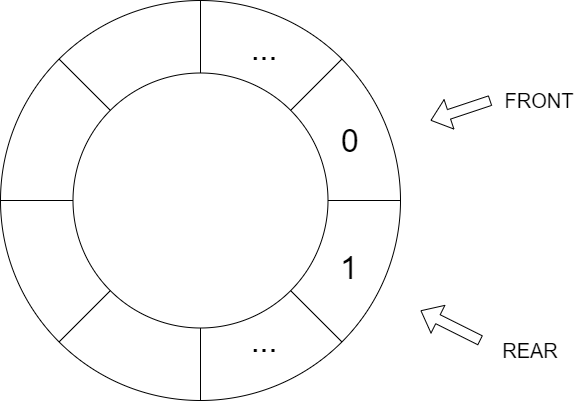
队列和广度优先搜索 队列 队列是一种特殊的线性表,因为它只能从一端插入,一端删除,即先进先出的效果,类似于现实中的排队。
性质
先进先出
一般从队头入队,队尾出队
空队列:front = rear
循环队列 由于队列中的元素只能从队头出,队尾进,因此如果不是特殊情况,采用顺序数组队列会浪费很多空间,并且它的使用也是有限制的(出队以后,队头之前的位置无法再被利用,而如果一直进队的话,数组总会被很快消耗完),因此可以考虑采用循环数组,将出队后的位置重新利用起来。
一般而言,循环队列的基本操作和特点如下:
队满:front = (rear + 1) % MAX_SIZE
队空:front = rear
插入元素:rear = (rear + 1) % MAX_SIZE
删除元素:front = (front + 1) % MAX_SIZE
其中MAX_SIZE是存放该队列的数组长度
队列为满时的情况
整体代码不算很难,但是要注意每次改变front 和 rear 的值时, 必须整除MAX_SIZE,以保证不会出现指针越界的情况。
代码如下(看看就好,跑不起来的):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #define F(qu) (qu->front) #define R(qu) (qu->rear) typedef int ElemType;#define MAX_SIZE 10 typedef struct c_queue int front;int rear;C_Queue *init_circle_queue (C_Queue *qu) ;int push (C_Queue *qu,ElemType *x) int pop (C_Queue *qu) int get_front (C_Queue *qu,ElemType *x) int isfull (C_Queue *qu) int isempty (C_Queue *qu) void destory_circle_queue (C_Queue *qu) void display (C_Queue *qu)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include "c_queue.h" C_Queue *init_circle_queue (C_Queue *qu) {malloc (sizeof (C_Queue));0 ;return qu;int isfull (C_Queue *qu) return qu->front == (qu->rear + 1 ) % MAX_SIZE;int isempty (C_Queue *qu) return qu->front == qu->rear;int push (C_Queue *qu,ElemType *x) if (isfull (qu)){perror ("The queue is full!\n" );return 0 ;1 ) % MAX_SIZE;return 1 ;int pop (C_Queue *qu) if (isempty (qu)){perror ("The queue is empty!\n" );return 0 ;1 ) % MAX_SIZE;return 1 ;int get_front (C_Queue *qu,ElemType *x) if (isempty (qu)){perror ("The queue is empty!\n" );return 0 ;return 1 ;void destory_circle_queue (C_Queue *qu) free (qu);return ;void display (C_Queue *qu) int i = qu->front;while (i != qu->rear){printf ("%d " , qu->data[i]);1 ) % MAX_SIZE;return ;
链式队列 链式队列的数据结构十分类似于链表,因此将链表加上头、尾指针后,就变成了链式队列。
基本操作
结点结构
结点中包含需要存储的数据和下一个结点的指针就行。也可以将头尾结点指针包装起来。
插入
先分析一般情况:当尾指针不为空时,直接将新结点插入到尾指针后面,再将尾指针指向这个新结点就好。
当尾指针为空:此时队列中无元素,将头尾指针指向这个新结点就好。
删除
也是先要分情况:当队列为空时,报错
队列较长:先把头指针保留下来,将头指针后移,再释放原先的头指针。
但是当队列只有一个元素时,最好还要保证尾指针不会变成野指针,因此做特殊情况处理,释放后将头尾指针指向空。
销毁队列
先判断队列是否为空,若不为空则从头结点开始依次释放(可以调用删除函数,也可以循环)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 typedef int ElemType;typedef struct node {struct node *next;typedef struct queue {Queue *init (Queue *qu) ;int isempty (Queue *qu) int push (Queue *qu, ElemType *x) int pop (Queue *qu) int get_front (Queue *qu, ElemType *x) void destory_queue (Queue *qu) void disp_queue (Queue *qu)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include "l_queue.h" #define D(qu) (qu->data) #define F(qu) (qu->front) #define R(qu) (qu->rear) #define N(qu) (qu->next) Queue *init (Queue *qu) {malloc (sizeof (Queue));NULL ;return qu;int isempty (Queue *qu) return qu->front == NULL ;int push (Queue *qu, ElemType *x) malloc (sizeof (QNode));NULL ;if (R (qu) == NULL ){F (qu) = R (qu) = s;return 1 ;return 1 ;int pop (Queue *qu) if (isempty (qu)){printf ("The queue is empty!\n" );return 0 ;F (qu);if (F (qu) == R (qu)){free (F (qu));F (qu) = R (qu) = NULL ;else {F (qu) = N (F (qu));free (tmp);return 1 ;int get_front (Queue *qu, ElemType *x) if (isempty (qu)){printf ("The queue is empty!\n" );return 0 ;D (F (qu));return 1 ;void destory_queue (Queue *qu) while (F (qu) != NULL ){pop (qu);return ;void disp_queue (Queue *qu) printf ("queue:\n" );if (F (qu) == NULL )return ;F (qu);while (p != R (qu)){printf ("%d " , D (p));N (p);printf ("%d\n" , D (p));return ;
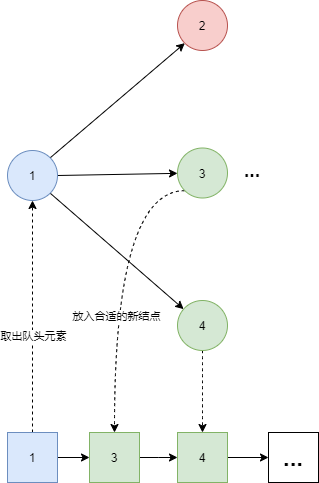
广度优先搜索(BFS) 概念 :广度优先搜索类似于一种横向式的搜索,对于它遇到的每一个合适的结点,都将放入考虑范围内,并且根据顺序依次访问,所以广度优先搜索常用于寻找最短路径 。
图结构中的BFS遍历 大致过程如下:首先访问初始点v,接着访问顶点v的所有未被访问过的邻接点v1,v2… 然后按照次序访问每一个未被访问过的顶点,直到找到所需要的顶点。由于始终优先访问最先被接触到的结点,因此适合用队列来实现。
通过下面的示意图能够很清晰的明白过程了。
大致的代码思路如下(该代码需要图的基本算法):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 typedef int ElemType;#define MAX_SIZE 100 typedef struct anode {int vertex;struct anode *next; int weight;typedef struct vnode {int isnode;typedef struct graph {int edges;int vertices;AdjGraph *init_with_file (AdjGraph *G, const char * filename) ; void insert (AdjGraph *G, int u, int v, int w) void destory_graph (AdjGraph *G) void disp_adjlist (AdjGraph *G)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include "graph_basic.h" #include "l_queue.h" void bfs (AdjGraph *G, int u, int v) init (qu);int visited[MAX_SIZE] = {0 };push (qu, &u);1 ;while (!isempty (qu)){int tmp;get_front (qu, &tmp); if (tmp == v){printf ("find!\n" );destory_queue (qu);return ;while (p != NULL ){int goal = p->vertex;if (visited[goal] == 0 ){1 ;push (qu, &goal);undel_pop (qu); printf ("not find!\n" );destory_queue (qu);return ;void find_shortest_path (AdjGraph *G, int u, int v) init (qu);int visited[MAX_SIZE] = {0 };push (qu, &u);1 ;NULL ;while (!isempty (qu)){int tmp;get_front (qu, &tmp); if (tmp == v){printf ("find! Road:\n" );while (t->parent != NULL ){printf ("%d<-" ,t->data);printf ("%d\n" ,t->data);destory_queue (qu);return ;while (p != NULL ){int goal = p->vertex;if (visited[goal] == 0 ){1 ;push (qu, &goal);undel_pop (qu); printf ("not find!\n" );destory_queue (qu);return ;
广义BFS 从广义上来说,BFS也是一种很常见的搜索方式,即处理完手里的所有情况之后,再去处理产生的新情况,下面是BFS寻找最小数值的伪代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 BFS function (params: root, target) init hash_table visited init a queue init step = 0 while queue not empty:if cur == target:return stepelse :for every suitable neighbors in cur: return -1